
지난 포스트에 이어 이번 포스트는 배열의 자료 구조 연산 과정을 알아보고 또 그 연산들의 계산 단계를 세어 보도록 하겠습니다.
읽기
배열에서는 특정 인덱스로 한 번에 접근해서 값을 확인할 수 있기에 읽기 연산의 계산 단계는 1 단계 입니다.
우선 컴퓨터는 주소를 알고 있다면 모든 메모리 주소에 대하여 한 번에 접근할 수 있습니다. 컴퓨터는 최초로 배열을 생성할 때 배열의 시작 메모리 주소를 별도의 메모리에 저장해 놓는데요. 읽기를 요청받으면 저장해놓은 배열의 시작 메모리 주소에 인덱스 값을 더하여 별도의 과정 없이 한 번에 접근합니다.
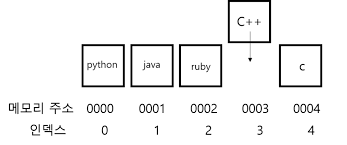
검색
읽기가 인덱스를 제공하고 값을 가져왔다면, 검색은 값을 제공하고 인덱스를 구합니다.
특정 값의 위치를 알 수 없기에 배열의 시작 메모리부터 순차적으로 확인하는 과정을 거칩니다. 우리는 이를 선형 탐색이라고 합니다.
크기가 N인 배열에서 찾고자 하는 값이 배열의 가장 앞에 위치한다면 1단계 만에 찾게 되겠지만 최악의 시나리오인 가장 뒤에 위치한다면 모든 원소를 확인해야 하기에 원소의 개수만큼인 N단계를 거치게 됩니다.

삽입
삽입 연산에서 데이터를 배열로 넣는 동작은 1단계입니다.
하여 비어있는 공간인 가장 뒤에 삽입한다면 1단계 만에 삽입 연산이 가능합니다. 하지만 비어있지 않은 공간에 삽입하는 경우는 어떻게 동작할까요?
해당 인덱스를 비우기 위해 그곳에 위치한 원소뿐만 아니라 뒤에 위치한 모든 원소들을 각각 1 인덱스를 뒤로 밀어내야만 합니다.
그렇다면 원소를 가장 앞에 넣는 경우에는 배열 내에 있는 모든 원소들을 1 인덱스 씩 뒤로 이동시킵니다. 단계를 표현해 보면 최악의 시나리오인 가장 앞에 넣는 경우 단계를 표현해보면 크기가 N인 배열에서 모든 원소의 이동 ( N 단계 ) + 배열에 넣는 동작 ( 1단계 )로 총 N + 1 단계를 거치게 됩니다.

삭제
삭제 역시 삽입과 유사한 과정으로 진행됩니다.
단순히 데이터를 배열에서 꺼내는 동작은 1단계입니다. 하지만 배열의 메모리 주소는 연속되어야 하기 때문에 삭제로 인해 생긴 빈 공간을 채워주어야 합니다. 삽입에서는 뒤로 밀어주었다면 삭제에서는 빈 공간을 메우기 위해 앞으로 당겨줍니다.
가장 뒤에 있는 원소를 삭제하였다면 1단계로 끝나겠지만 최악의 시나리오인 가장 앞의 원소를 삭제했다면 배열 안에 남아있는 모든 원소들을 앞으로 당겨주어야 합니다. 가장 앞의 원소를 삭제하였을 때를 단계로 표현해 보면 크기가 N인 배열에서 삭제한 원소를 제외하고 남아있는 배열에서 꺼내는 동작 ( 1단계 ) + N-1개의 원소의 이동 ( N-1단계 )으로 총 N단계에 걸쳐 삭제가 이뤄지게 됩니다.
마치며
이번 포스트에서는 배열의 자료구조 연산에 대해서 알아봤습니다. 간단한 연산이지만 최대한 풀어 설명해 보았는데 잘 전달되었는지 궁급합니다. 매 연산마다 최악의 시나리오를 고려하는 이유는 자료구조 간 연산의 성능을 비교할 때는 가장 시간이 오래 걸리는 경우를 상정하고 비교하기 때문입니다.
항상 좋은 글을 쓸 수 있도록 노력하겠습니다.
감사합니다.
관련 게시물
배열 - 가장 기초적인 자료구조 ( 1 )
이번 포스트에서는 컴퓨터 과학에서 가장 기초적인 자료구조라고 할 수 있는 배열에 대해서 포스팅해보겠습니다. 배열에 대한 분석과 더불어 알고리즘에서 말하는 "속도" ( 시간 복잡도 ) 란 무
hy1as.tistory.com
배열 - 가장 기초적인 자료구조 ( 3 )
배열 시리즈의 마지막 포스트입니다. 이번 포스트에서는 배열 자료구조에 제약사항 한 가지를 더한 집합이라는 자료구조에 대해서 알아보며 특정 조건으로 인해 달라지는 연산의 효율성에 대
hy1as.tistory.com
'Computer Science > 자료구조' 카테고리의 다른 글
| 연결리스트 : 대량 삽입과 삭제에 유리한 Node 기반 자료구조 (0) | 2023.03.18 |
|---|---|
| 스택과 큐 - 제약을 통한 문제 해결 전략 (0) | 2023.03.11 |
| 해시 테이블 - 빠른 검색 (0) | 2023.03.11 |
| 배열 - 가장 기초적인 자료구조 ( 3 ) (0) | 2023.03.03 |
| 배열 - 가장 기초적인 자료구조 ( 1 ) (0) | 2023.03.03 |